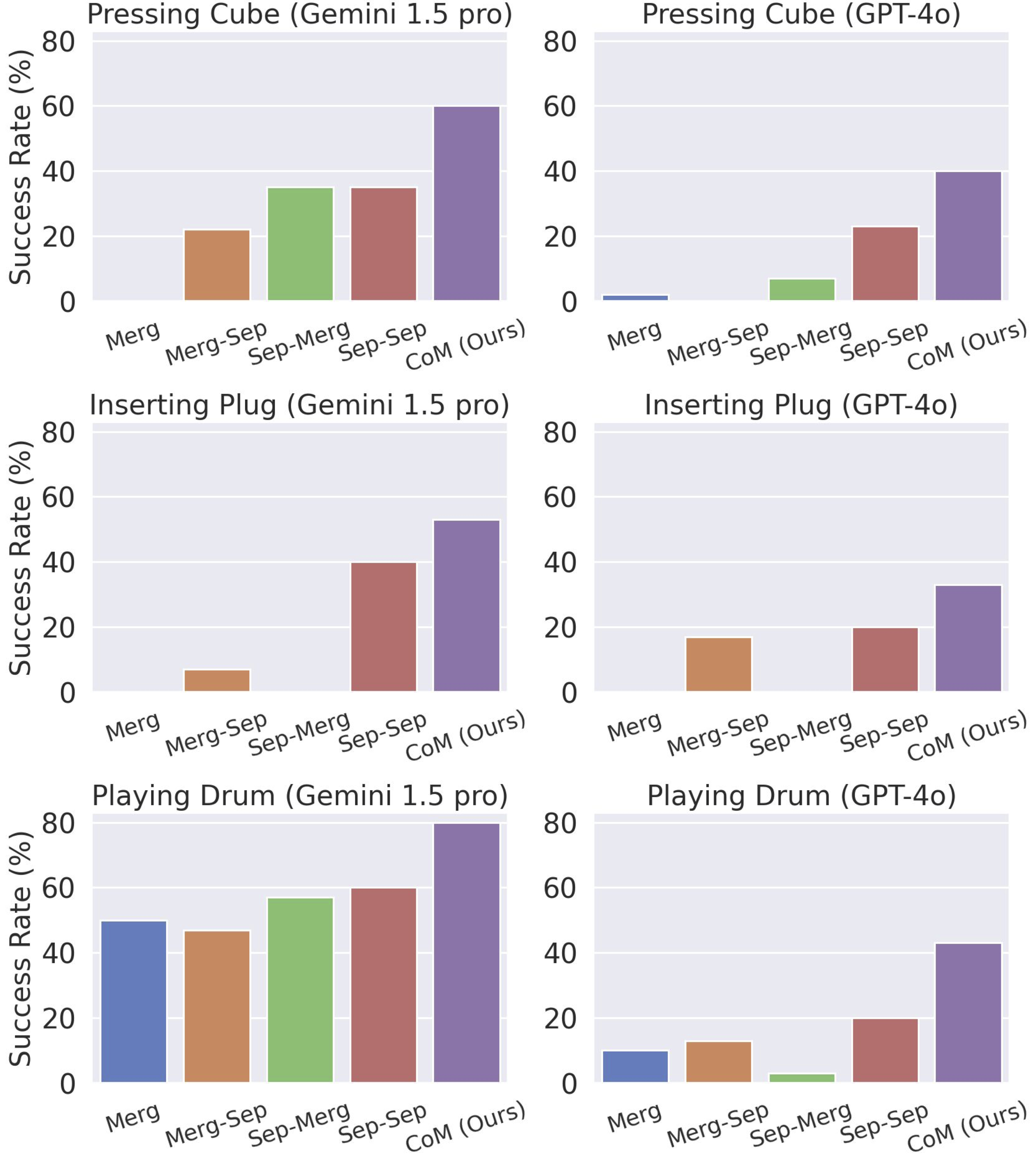

We evaluate our approach on four manipulation tasks that require precise control parameters:
- Opening Bottle: A bi-manual task requiring precision in grasping and twisting. In real-world evaluations, we tested with 7 different bottles (6 unseen) and deployed on two robot platforms (bi-manual ViperX and KUKA).
- Inserting Plug: Requires varying force application during different phases of manipulation. For testing generalization, we randomly placed the plug, power strip, and box in different configurations.
- Playing Drum: Demands precise control of force and timing. We tested with different drumming beats to evaluate adaptability to various rhythmic patterns.
- Wiping Board: Tests force-controlled surface interaction. We evaluated with marker drawings of different shapes and varying positions on the board.